
For a variety of reasons, we see situations where an organization’s production environment is in the Cloud, but their staging/testing environment is still hosted on-premises. In some cases, to facilitate testing, development, debugging, or reporting, a backup of production data is manually restored from production to the staging environment on a regular basis. Herein lies an opportunity for process automation that is lightweight, less complex, and saves time. This article walks you through the process of automating a restore of an AWS RDS database to an on-prem SQL Server by taking advantage of the AWS RDS Native Backup and Restore feature.
This feature allows a .bak backup file to be created by running a SQL command, and then saved to an S3 bucket. This step can be automated using the SQL Server Agent feature of Microsoft’s SQL Server. Once the .bak file is created, it then needs to be downloaded from the S3 bucket to the on-prem SQL server, and restored to the database. This can also be automated using SQL Server Agent, a PowerShell command, and a few SQL commands. The details of how to accomplish this are as follows:
Setup
1. AWS provides great documentation on the Native Backup and Restore feature. Review the prerequisites listed in the ‘Setup’
2. The 3 main prerequisites are:
- An Amazon S3 bucket to store your backup files.
- An AWS Identity and Access Management (IAM) role to access the bucket.
- The SQLSERVER_BACKUP_RESTORE option added to an option group on your DB instance.
Create SQL Job on RDS to create .bak file and save to S3
1. Connect to the production RDS SQL instance in SQL Server Management Studio
2. Expand ‘SQL Server Agent’ in Object Explorer
3. Right-click on Jobs, and select ‘New Job’
- This job will only contain one step. The type will be T-SQL. The SQL statement will invoke the RDS Backup functionality, and save the .bak file to the specified S3 bucket.
- exec msdb.dbo.rds_backup_database
@source_db_name='[NameOfProductionDatabase]',
@s3_arn_to_backup_to='arn:aws:s3:::[S3bucket]/[backupFileName].bak',
@overwrite_S3_backup_file=1;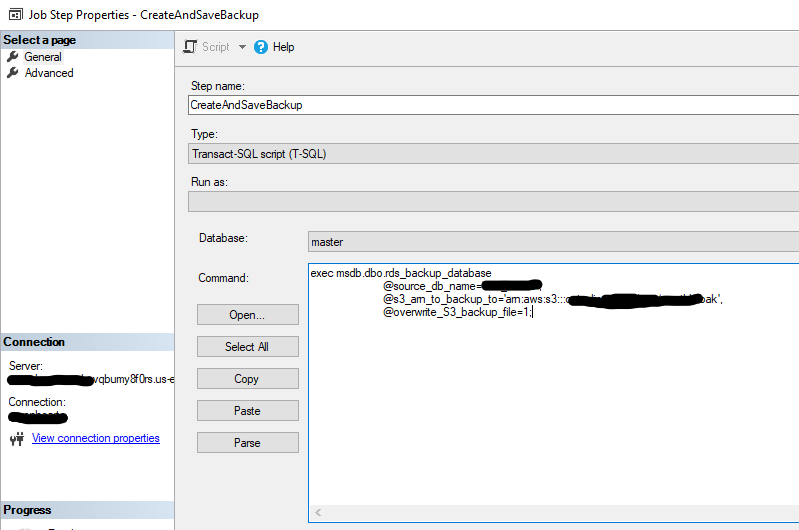
4. For more information about the details about this command, and other options not used in this example, see AWS documentation
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/SQLServer.Procedural.Importing.html#SQLServer.Procedural.Importing.Native.Using.Backup
5. Add Schedule to the Job to invoke it at the desired frequency
Create SQL Job on on-prem SQL Server to download .bak and restore to DB
1. Connect to the on-prem SQL Server
2. Create new SQL Server Agent Job. The first step will be of type PowerShell, the rest will be T-SQL.
3. Add step 1 - CopyBakFromS3
- (New-Object System.Net.WebClient).DownloadFile("https://[S3bucketPathToBakFile].bak", "[LocalPathOnServer].bak")
4. Add step 2 – TakeDBOffline
- ALTER DATABASE [databaseName] SET OFFLINE WITH ROLLBACK IMMEDIATE
5. Add step 3 – RestoreDB
- restore database [databaseName]
from disk = '[LocalPathOnServer].bak'
with replace
6. Add step 4 – BringDBOnline
- ALTER DATABASE [databaseName] SET ONLINE WITH ROLLBACK IMMEDIATE
7. Add step 5 – PostProcessing (depending on the specific needs of the database)
- alter database [databaseName] set NEW_BROKER with rollback immediate
go
exec sp_change_users_login 'Update_One', '[loginName], '[loginName]'
go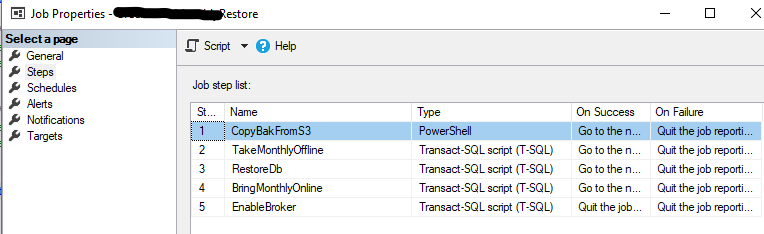
8. Add Schedule to the Job to invoke it at the desired frequency
Finish and Test!
If your staging/testing environment is still located on-premises, but you are looking for a lightweight and cost- effective solution for backing up and restoring your data, AWS has the tools you need.  for more tips on how to take full advantage of AWS features.
for more tips on how to take full advantage of AWS features.